Pandas
pandas is a Python library for data analysis. It offers a number of data exploration, cleaning and transformation operations that are critical in working with data in Python.
pandas build upon numpy and scipy providing easy-to-use data structures and data manipulation functions with integrated indexing.
The main data structures pandas provides are Series and DataFrames. After a brief introduction to these two data structures and data ingestion, the key features of pandas this notebook covers are:
- Generating descriptive statistics on data
- Data cleaning using built in pandas functions
- Frequent data operations for subsetting, filtering, insertion, deletion and aggregation of data
- Merging multiple datasets using dataframes
- Working with timestamps and time-series data
Additional Recommended Resources:
- pandas Documentation: http://pandas.pydata.org/pandas-docs/stable/
- Python for Data Analysis by Wes McKinney
- Python Data Science Handbook by Jake VanderPlas
Let's get started with our first pandas notebook!
import pandas as pd
Introduction to pandas Data Structures
*pandas* has two main data structures it uses, namely, *Series* and *DataFrames*.
pandas Series
pandas Series one-dimensional labeled array.
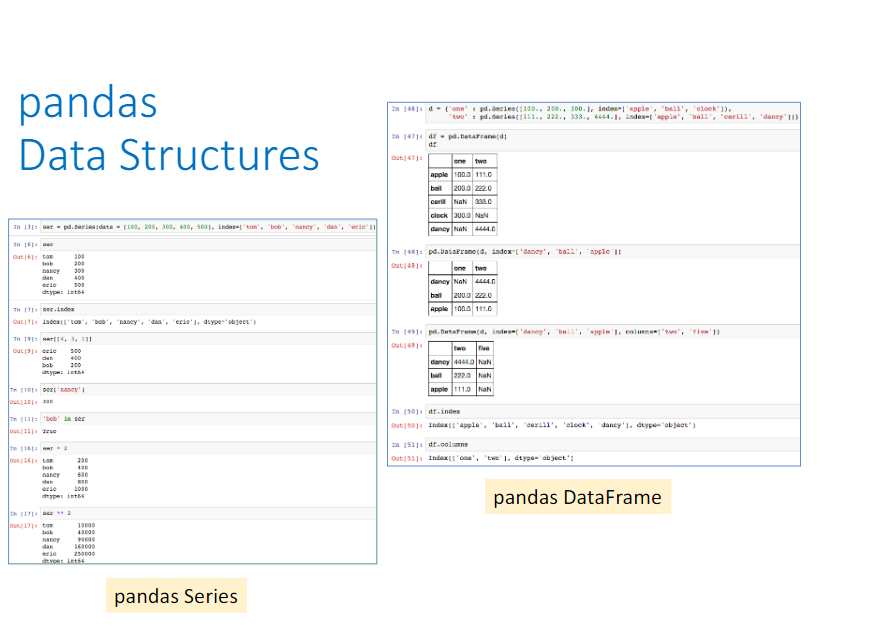
ser = pd.Series([100, 'foo', 300, 'bar', 500], ['tom', 'bob', 'nancy', 'dan', 'eric'])
print(ser)
ser.index
ser.loc[['nancy','bob']]
ser[[4, 3, 1]]
ser.iloc[2]
'bob' in ser
print(ser)
print(ser*2)
ser[['nancy', 'eric']] ** 2
pandas DataFrame
pandas DataFrame is a 2-dimensional labeled data structure.
Create DataFrame from dictionary of Python Series
d = {'one' : pd.Series([100., 200., 300.], index=['apple', 'ball', 'clock']),
'two' : pd.Series([111., 222., 333., 4444.], index=['apple', 'ball', 'cerill', 'dancy'])}
df = pd.DataFrame(d)
df
Other way to do the same
d = {'one' : [100., 200.,float("NaN"), 300., float("NaN")],'two':[111., 222., 333., float("NaN"),4444.],"tmp_index":['apple', 'ball', 'cerill', 'clock', 'dancy']}
df=pd.DataFrame(data=d)
df.set_index("tmp_index",inplace=True)
df.index.name = None
df
d = {'one' : pd.Series([100., 200., 300.], index=['apple', 'ball', 'clock']),
'two' : pd.Series([111., 222., 333., 4444.], index=['apple', 'ball', 'cerill', 'dancy'])}
df = pd.DataFrame(d)
pd.DataFrame(d, index=['dancy', 'ball', 'apple'])
pd.DataFrame(d, index=['dancy', 'ball', 'apple'], columns=['two', 'five'])
Create DataFrame from list of Python dictionaries
data = [{'alex': 1, 'joe': 2}, {'ema': 5, 'dora': 10, 'alice': 20}]
pd.DataFrame(data)
pd.DataFrame(data, index=['orange', 'red'])
pd.DataFrame(data, columns=['joe', 'dora','alice'])
Basic DataFrame operations
df
df['one']
df['three'] = df['one'] * df['two']
df
df['flag'] = df['one'] > 250
df
three = df.pop('three')
three
df
del df['two']
df
df.insert(2, 'copy_of_one', df['one'])
df
df['one_upper_half'] = df['one'][:2]
df
df.dropna(axis=0,thresh=2)
Case Study: Movie Data Analysis
This notebook uses a dataset from the MovieLens website. We will describe the dataset further as we explore with it using pandas.
Download the Dataset¶
Please note that you will need to download the dataset.
Here are the links to the data source and location:
- Data Source: MovieLens web site (filename: ml-20m.zip)
- Location: https://grouplens.org/datasets/movielens/
Once the download completes, please make sure the data files are in a directory called movielens
Let us look at the files in this dataset using the UNIX command ls.
%%bash
ls movielens/Large/
%%bash
cat movielens/Large/movies.csv | wc -l
%%bash
cat movielens/Large/ratings.csv | wc -l
%%bash
head -5 ./movielens/Large/ratings.csv
Use Pandas to Read the Dataset
In this notebook, we will be using three CSV files:
- ratings.csv : userId,movieId,rating, timestamp
- tags.csv : userId,movieId, tag, timestamp
- movies.csv : movieId, title, genres
Using the read_csv function in pandas, we will ingest these three files.
movies = pd.read_csv('./movielens/Large/movies.csv', sep=',')
print(type(movies))
movies.head(15)
tags = pd.read_csv('./movielens/Large/tags.csv', sep=',')
tags.head()
ratings = pd.read_csv('./movielens/Large/ratings.csv', sep=',', parse_dates=['timestamp'])
ratings.head()
For current analysis, we will remove the Timestamp ( we could get to it later if you want)
del ratings['timestamp']
del tags['timestamp']
Data Structures
Series
row_0 = tags.iloc[0]
print(type(row_0))
print(row_0)
row_0.index
row_0['userId']
'rating' in row_0
row_0.name
row_0 = row_0.rename('first_row')
row_0.name
Descriptive Statistics
Let's look how the ratings are distributed!
ratings.describe()
ratings.mode()
ratings.corr()
filter_2 = ratings.loc[ratings['rating'] > 0]
filter_2.groupby("movieId").mean()
Data Cleaning: Handling Missing Data
movies.shape
Is there any row Null?
movies.isnull().any()
Nice!!, so we do not have to worry about this!
ratings.shape
ratings.isnull().any()
Nice!!, so we do not have to worry about this!
tags.shape
tags.isnull().any()
Unfortunately we will have to deal with NaN values in this data set
tags = tags.dropna()
We check agaiin if there is any row null
tags.isnull().any()
Thats nice! Nonetheless, notice that the number of lines have reduced.
tags.shape
Data Visualization
import matplotlib.pylab as plt
ratings.hist(column='rating', figsize=(15,10),bins=10)
plt.show()

Getting information from columns
tags['tag'].head()
movies[['title','genres']].head()
ratings[-10:]
ratings.tail(10)
tag_counts = tags['tag'].value_counts()
tag_counts.head().plot(kind='bar', figsize=(12,8))

tag_counts.head(60).plot(kind='bar', figsize=(12,8))

tag_counts[60:100].plot(kind='bar', figsize=(12,8))

Filters for Selecting Rows
is_highly_rated = ratings['rating'] >= 4.0
ratings[is_highly_rated].head()
is_animation = movies['genres'].str.contains('Animation')
movies[is_animation].head(15)
ratings_count = ratings[['movieId','rating']].groupby('rating').count()
ratings_count
Group By and Aggregate
average_rating = ratings[['movieId','rating']].groupby('movieId').mean() # We are not interested in the user that voted for it
average_rating.head()
sorted_average_rating=average_rating.sort_values(by="rating",ascending=False)
sorted_average_rating.head()
Option 2:¶
Do not sort the list but intead ask where we have that the rating score is $5.0$
average_rating.loc[average_rating.rating==5.0].head()
But since we do not understand to what this Id movie is related, we would like to see intead the name of the movie. To do that, we need to see in the movies DataFrame
id_movie=average_rating.loc[average_rating.rating==5.0].index
movies.loc[movies.movieId.isin(id_movie)].head()
Merge Dataframes
tags.head()
movies.head()
t = pd.merge(movies,tags, on='movieId', how='inner')
t.head()
Check More examples: http://pandas.pydata.org/pandas-docs/stable/merging.html
Combine aggreagation, merging, and filters to get useful analytics
avg_ratings = ratings.groupby('movieId', as_index=False).mean()
del avg_ratings['userId']
avg_ratings.head()
box_office = pd.merge(movies,avg_ratings, on='movieId', how='inner')
box_office.tail()
is_highly_rated = box_office['rating'] >= 4.0
box_office[is_highly_rated].tail()
is_comedy = box_office['genres'].str.contains('Comedy')
box_office[is_comedy].head()
box_office[is_comedy & is_highly_rated].head()
Vectorized String Operations
movies.head()
Split 'genres' into multiple columns
movie_genres = movies['genres'].str.split('|', expand=True)
movie_genres.head(10)
Add a new column for comedy genre flag
movie_genres['IsComedy'] = movies['genres'].str.contains('Comedy')
movie_genres.head()
Extract year from title e.g. (1995)
movies['year'] = movies['title'].str.extract('.*\((.*)\).*', expand=True)
More here
Parsing Timestamps
Timestamps are common in sensor data or other time series datasets. Let us revisit the tags.csv dataset and read the timestamps!tags = pd.read_csv('./movielens/Large/tags.csv', sep=',')
tags.dtypes
Unix time / POSIX time / epoch time records
time in seconds
since midnight Coordinated Universal Time (UTC) of January 1, 1970
tags.head(5)
tags['parsed_time'] = pd.to_datetime(tags['timestamp'], unit='s')
Data Type datetime64[ns] maps to either
tags['parsed_time'].dtype
tags.head(2)
Selecting rows based on timestamps
greater_than_t = tags['parsed_time'] > '2015-02-01'
selected_rows = tags[greater_than_t]
print(tags.shape, selected_rows.shape)
Sorting the table using the timestamps
tags.sort_values(by='parsed_time', ascending=True)[:10]
Average Movie Ratings over Time
Are Movie ratings related to the year of launch?¶
average_rating = ratings[['movieId','rating']].groupby('movieId', as_index=False).mean()
average_rating.tail()
joined = pd.merge(movies,average_rating, on='movieId', how='inner')
joined.head()
joined.corr()
yearly_average = joined[['year','rating']].groupby('year', as_index=False).mean()
yearly_average.head(10)
yearly_average.plot(x='year', y='rating', figsize=(12,8), grid=True)
plt.show()
